Sparse Signal Loop
There is a very particular kind of optimism that agent work seems to attract.
It goes something like this: perhaps the model is already mostly capable, and what looks like a reasoning failure is actually a management failure. Maybe the signal is too mushy. Maybe the loop is too forgetful. Maybe the model needs a better place to keep state than a chat transcript that keeps swelling until nobody, least of all the model, wants to read it.
If that is true, then changing the harness should not be a cosmetic intervention. It should produce qualitatively different behavior.
I tested this directly. The core question is simple: Does sparse feedback (one violated criterion) help an RLM more than dense feedback (a total score)? More precisely, does limiting the judge to a single complaint change the refinement strategy an RLM develops, and does that harness extract more value from sparsity than vanilla iterative refinement?
I like this question because it is sharp enough to kill its own framing. If sparse feedback helps both harnesses equally, the feedback format is doing the work. If RLM helps specifically under sparse feedback, then the harness is doing something mechanistically different. If neither happens, then a surprising amount of agent-flavored rhetoric collapses into "we changed the prompt and hoped."
These experiments do not yet answer that question in the strongest RL sense. What they do, and quite usefully, is answer the prompt-time version of it. Before any weights are updated, how much does behavior move if we change the shape of judge feedback, the location of working memory, or the persistence mechanism for process notes?
That matters more than it sounds. If these prompt-only interventions already swing outcomes a lot, then the harness really is part of the object we are studying. If they do not, then the "manager" in the mismanaged geniuses story might be less mysterious than advertised.
Flow (how to read this note)
- The Setup: What I Actually Built
- Phase 0: The Core 2x2
- Phase 1: Where Should the Notebook Live?
- Phase 2: Does Procedure Persist?
- Efficiency Is Part Of The Result
- So What does this lead to?
- Caveats
- What I Would Try Next
- Final Word
The Setup: What I Actually Built
The experiment scaffold is disciplined about what changes across phases.
At the base, we have a plain 2×2:
- harness:
chatvsrlm - judge feedback: dense total-score feedback vs sparse single-criterion feedback
That is Phase 0. Everything else is a perturbation on this core.
Phase 1 adds a modest intervention: a structured checklist / hypothesis log / failure log. The only variable is where that notebook lives:
- For chat harnesses, it lives in assistant messages.
- For RLM, it is either kept in those same assistant messages as an ablation or persisted in files in the workspace.
Phase 2 asks whether procedure can persist, not just scratchwork:
- Chat gets
chat_no_fileandchat_system_reinject(where tagged process blocks get reinserted at the start of the next turn). - RLM gets a skill-file arm, where the model updates a persistent process note after bad judge calls. This is literal memory: an actual text file in the sandbox.
The two benchmark families are importantly different:
- LongBench-Pro (LBP) is long-context question answering, retrieval, and clustering. The chat harness revises answers in conversation; the RLM harness works through a REPL over the materialized long context. Primary reward here is the judge, but we also log task metrics (accuracy, F1, NDCG, etc.).
- Mini SWE Agent Plus is code repair inside sandboxes. Here the primary reward is actual task solve rate from the test harness. The judge is only an in-loop helper. This distinction turns out to matter a lot.
A wrinkle: Phases 1 and 2 run on narrower, harder slices (LBP clustering at 32k; Mini SWE narrowed to Django). So read these as independent experiments, not a time-series.
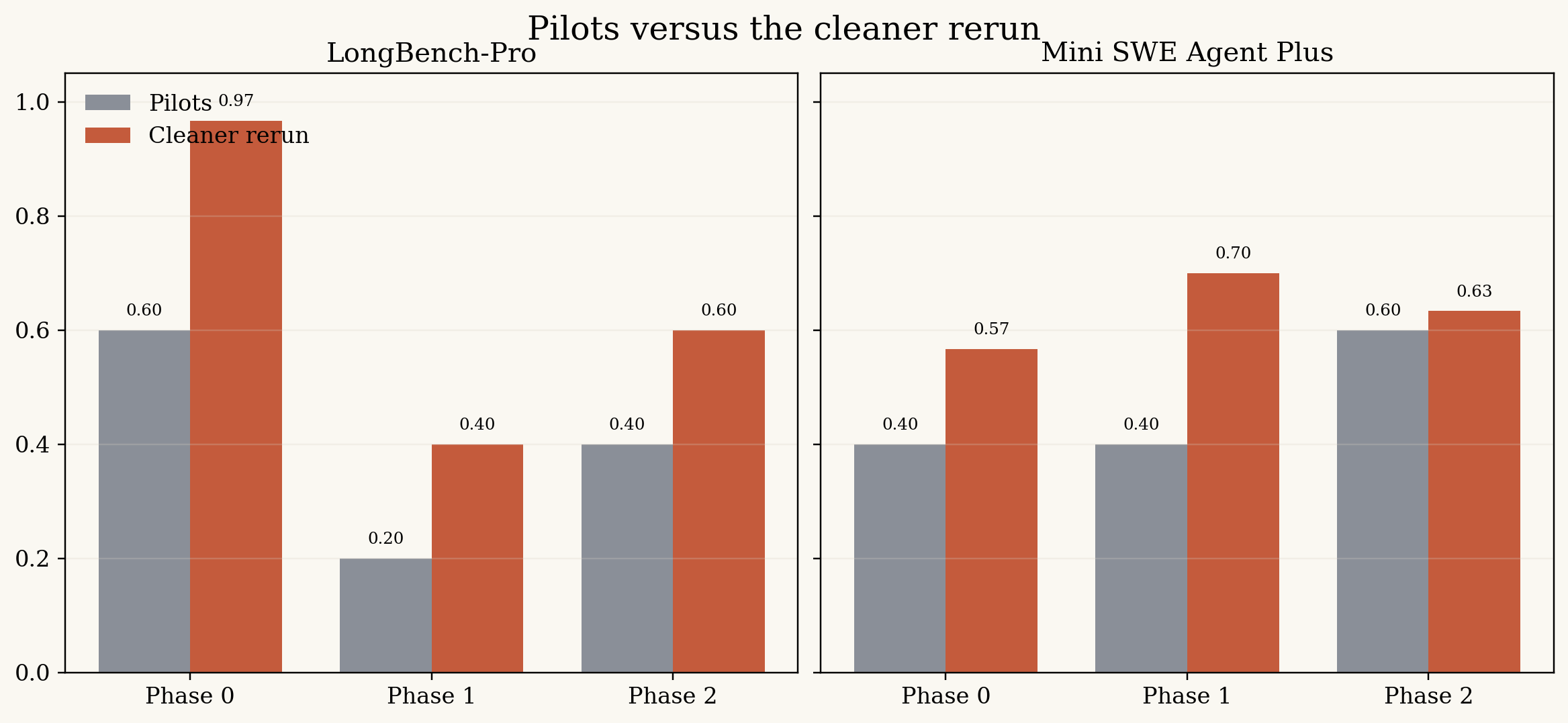
The cleaner rerun usually beat the pilots, though not by a dramatic or uniform margin. This comparison also mixes model families, so I take it as orientation rather than proof.
Phase 0: The Core 2×2
Phase 0 is the central question in its cleanest form.
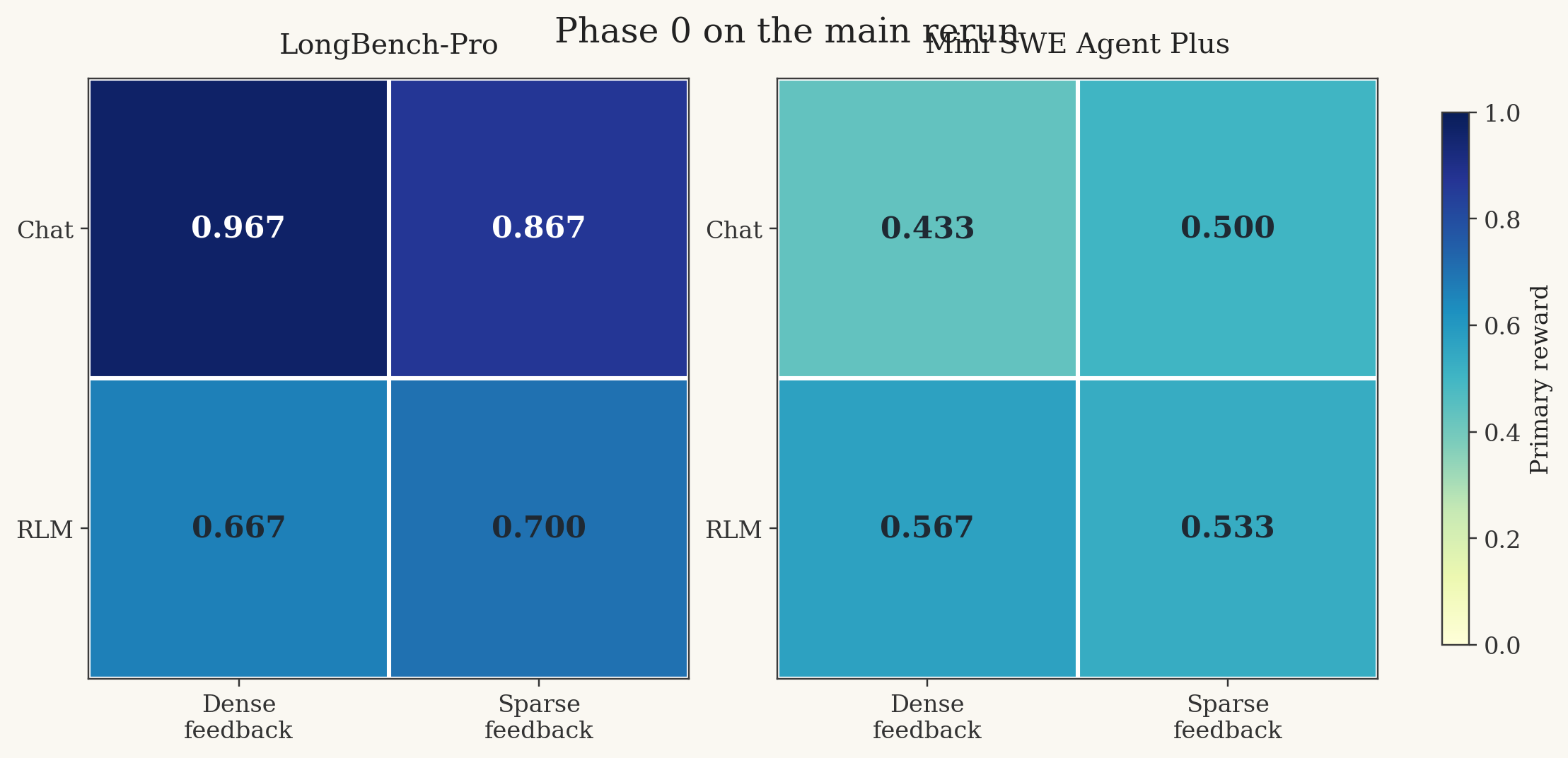
Primary reward on the cleaner rerun. Same 2×2, two very different benchmark families.
The answer is not a theorem. It is benchmark-shaped.
LongBench-Pro
On the full Phase 0 LongBench-Pro run, the plain chat loop won comfortably.
| Arm | Reward / Judge YES | Avg task metric |
|---|---|---|
chat__total_score | 0.9667 | 0.6396 |
chat__single_criterion | 0.8667 | 0.6525 |
rlm__single_criterion | 0.7000 | 0.5351 |
rlm__total_score | 0.6667 | 0.4368 |
If you wanted a quick headline: on long-context tasks, a plain iterative chat loop with dense rubric feedback was simply harder to beat than the fancier harness.
But the more interesting detail is that the dense chat arm was not just better; it was also faster. In the raw rollouts, it averaged 3.63 turns and about 149,192 tokens per rollout, whereas sparse chat averaged 6.10 turns and about 495,834 tokens per rollout. So the denser signal was, in practice, the cheaper one, because the loop converged earlier.
There is also a small splinter in these numbers that I do not think should be ignored. The dense-chat arm reached 29 judge acceptances out of 30 rollouts, but its task metric was still only 0.6396. Looking at the raw rows, two T3.2 Single-Hop Fact QA examples were judge-accepted with task_metric_reward = 0.0; the model answered simply [Answer] D or [Answer] C, which the judge accepted, while the benchmark metric did not. That is not a scandal. It is just a reminder that "the judge" and "the benchmark" are not the same object, even when the scoreboard tries to make them look like one.
And that, already, is a useful result: sparse feedback did not unlock some hidden RLM advantage here. If anything, the loop with the smallest conceptual overhead won.
Mini SWE Agent Plus
Mini SWE is more annoying, in the productive sense.
| Arm | Solved rate | Judge YES |
|---|---|---|
chat__single_criterion | 0.5000 | 0.6333 |
chat__total_score | 0.4333 | 0.3333 |
rlm__single_criterion | 0.5333 | 0.7333 |
rlm__total_score | 0.5667 | 0.8667 |
So the cross-over goes in opposite directions:
- Chat preferred sparse feedback.
- RLM preferred dense feedback.
This is almost comically uncooperative if what you wanted was a clean one-line conclusion. But as a measurement, it is actually quite informative. It suggests that "feedback sparsity" is not a standalone variable with a universal sign. It interacts with the task and with the loop.
My rough reading is this:
- For chat-on-code-repair, one crisp complaint may be enough. The loop is already structurally simple, so dense rubric lines mostly add more surface area to overfit.
- For RLM-on-code-repair, dense feedback may be acting as a more useful local search landscape. The harness has more degrees of freedom, and the extra rubric structure gives it more to grab onto.
That is still just a read, not a proof. But it is at least compatible with the data, which is more than can be said for many armchair theories of agent behavior.
Phase 1: Where Should the Notebook Live?
Phase 1 is one of those interventions that sounds almost too modest to matter. The model is told to maintain:
- a short checklist
- a one- or two-line hypothesis log
- a one-line "what failed last time"
The only real variable is whether those notes live in chat or in files.
This is, in a very literal sense, a test of external working memory. Not memory in the grand cognitive sense. Just a notebook.
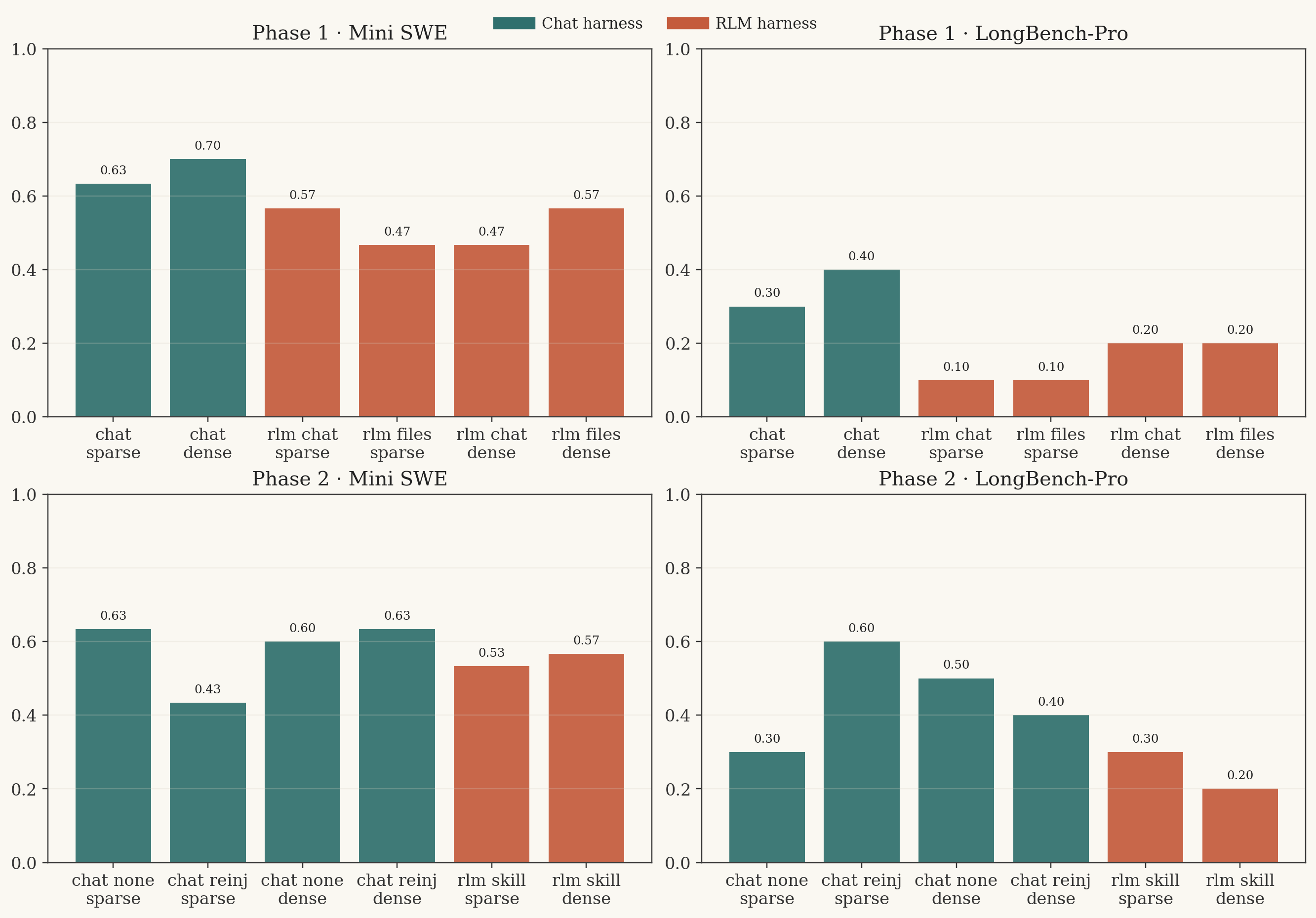
Phase 1 and Phase 2 on the cleaner rerun. The later LongBench-Pro phases are on a harder clustering slice, so compare within-phase, not across all phases.
Mini SWE Phase 1
The cleanest result in Phase 1 is that the simplest arm won again.
| Arm | Solved rate |
|---|---|
chat__total_score__mem_chat | 0.7000 |
chat__single_criterion__mem_chat | 0.6333 |
rlm__total_score__mem_repl_files | 0.5667 |
rlm__single_criterion__mem_chat | 0.5667 |
rlm__single_criterion__mem_repl_files | 0.4667 |
rlm__total_score__mem_chat | 0.4667 |
So: yes, the notebook helps a bit relative to Phase 0, but no, putting it in files does not obviously save the RLM. In fact, file-backed notes were sometimes worse than chat-backed notes.
What did happen is slightly more awkward. The RLM arms often looked better to the judge than to the tests. On the dense-feedback arms, judge YES rose to 0.9000, but solved rate sat at 0.4667 and 0.5667. In raw-count terms, that means a large pile of "judge says yes, tests say no."
That gap matters because it changes how one should interpret Phase 1. If the question is "can a better notebook help the model look more coherent to an LLM judge?", then maybe yes. If the question is "does it help the agent actually fix code?", the answer is much weaker.
LongBench-Pro Phase 1
Here the result is harsher.
| Arm | Reward |
|---|---|
chat__total_score__mem_chat | 0.4000 |
chat__single_criterion__mem_chat | 0.3000 |
rlm__total_score__mem_chat | 0.2000 |
rlm__total_score__mem_repl_files | 0.2000 |
rlm__single_criterion__mem_chat | 0.1000 |
rlm__single_criterion__mem_repl_files | 0.1000 |
Because this is the Phase 1 slice, we are now on five clustering examples at 32k, two rollouts each. So I would not try to squeeze universal truths out of the second decimal place here. But the direction is not subtle. On this slice, persistent notes in files did not rescue the RLM at all.
The charitable interpretation is that the hard part on this LBP slice is not remembering the last failed guess. It is decomposing the clustering problem quickly enough that the next guess is materially better. A notebook does not automatically give you that abstraction.
This is the first place where the broader "mismanaged geniuses" intuition started to feel useful to me. The problem is not "more state good." The problem is: what is the right decomposition language? A checklist stored in the wrong abstraction is just a longer way of being confused.
Phase 2: Does Procedure Persist?
Phase 2 is the closest thing here to a harness-native continual-learning question.
Not continual learning in the parametric sense. No weights are being updated. No cross-episode competence is being internalized. But there is an attempt to preserve reusable procedure:
- what kinds of judge failures to look for
- what to check before submitting
- what habits reduce wasted tool calls
The setup is careful about this. The prompts explicitly ban task spoilers and gold spans. The skill file is supposed to contain procedure only.
That is exactly why the results are interesting. If the procedure channel helps, it means the loop can accumulate useful meta-behavior without being handed answers.
Mini SWE Phase 2
This is where the numbers become a little mischievous.
On actual solved rate, the best Phase 2 Mini SWE cells were both chat arms:
| Arm | Solved rate |
|---|---|
chat__single_criterion__chat_no_file | 0.6333 |
chat__total_score__chat_system_reinject | 0.6333 |
The RLM skill-file arms did not beat them:
| Arm | Solved rate |
|---|---|
rlm__single_criterion__rlm_skill_file | 0.5333 |
rlm__total_score__rlm_skill_file | 0.5667 |
So if the hoped-for story was "sparse signal plus RLM plus a skill file produces a qualitatively better refinement regime," the answer here is no, not yet.
And then there is the judge.
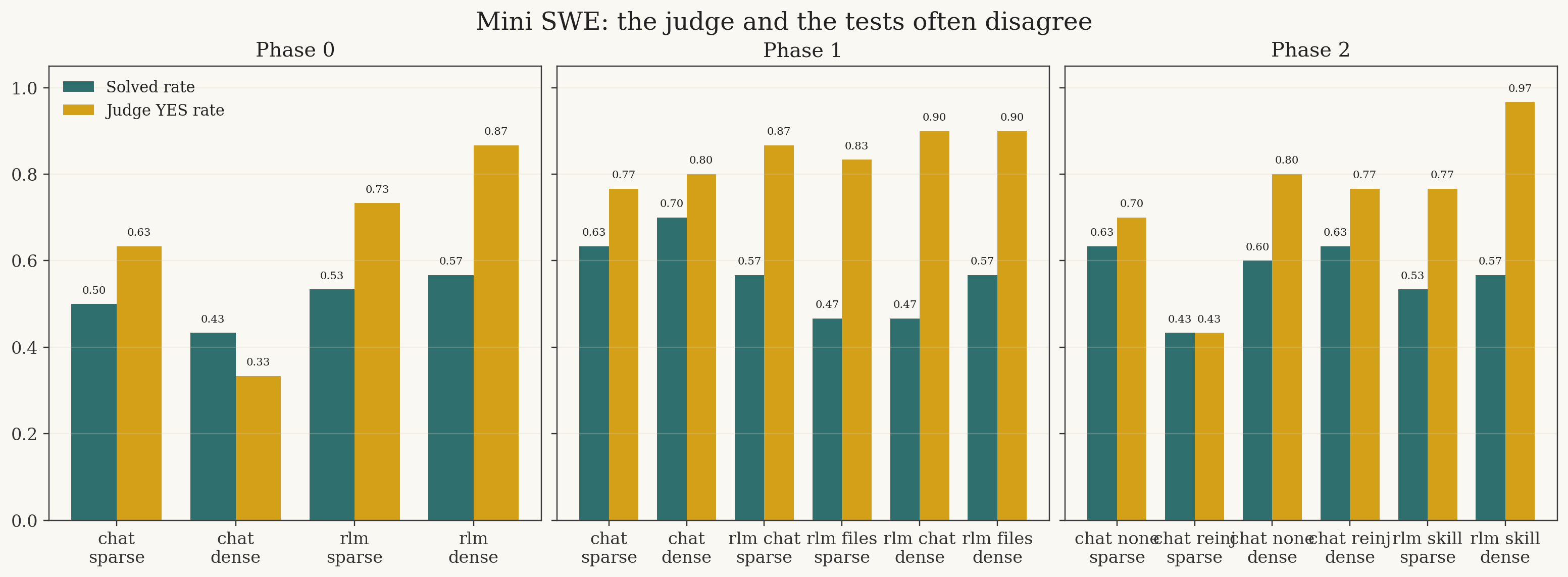
On Mini SWE, especially for the RLM arms, the in-loop judge is often substantially more optimistic than the test harness.
The densest skill-file arm, rlm__total_score__rlm_skill_file, was judged correct on 29 out of 30 rollouts, for a judge YES rate of 0.9667. But it only actually solved 17 out of 30, i.e. 0.5667. That is 12 judge-yes / test-no false positives in a single cell.
I do not think one can look at that and say "the skill file worked" without immediately asking "worked at what?"
It may well have helped the model learn how to produce the kind of diff-and-explanation bundle the judge likes. That is not nothing. But it is not the same as learning a better repair policy. In this setting, the skill file seems at least partly capable of preserving judge-facing procedure rather than task-facing procedure.
One caveat: the sparse reinjection chat arm on Mini SWE was also contaminated by 8 sandbox startup errors. Its 0.4333 should therefore be read with more suspicion than the other Phase 2 cells. This is exactly the kind of thing raw rollout inspection is useful for; the top-line summary alone makes it look like a clean behavioral loss.
LongBench-Pro Phase 2
LongBench-Pro Phase 2 is, to me, more encouraging for lightweight memory than for explicit file-backed skills.
| Arm | Reward |
|---|---|
chat__single_criterion__chat_system_reinject | 0.6000 |
chat__total_score__chat_no_file | 0.5000 |
chat__total_score__chat_system_reinject | 0.4000 |
chat__single_criterion__chat_no_file | 0.3000 |
rlm__single_criterion__rlm_skill_file | 0.3000 |
rlm__total_score__rlm_skill_file | 0.2000 |
The best arm here is the chat loop with sparse feedback and system reinjection. Not the file. Not the heavier harness. Just a weak carry-over mechanism that re-exposes a tagged process block on the next turn.
That result made me pause a bit, because it is almost the opposite of the durable skill-file intuition. But perhaps it should not be so surprising. Reinjection is opinionated. It forces the persistent state to be short, local, and immediately legible to the next step. A free-form skill file has more expressive power, but also more ways to become vague, bloated, or merely ceremonial.
Again: the question is not whether memory exists. The question is what language that memory is written in.
Efficiency Is Part Of The Result
There is another way to read these runs that the reward tables hide a bit.
On some cells, the harness that loses on absolute reward still wins on cost. On others, the winner is just better across the board. That distinction matters because agent work has a bad habit of grading itself only on "best answer eventually," even when the scaffold quietly multiplies latency and token burn.
I am using two simple quantities from the run artifacts:
- total tokens, which here is the mean input-plus-output tokens per rollout
- mean rollout time, computed from
rollout_time_ms_sum / num_rollouts
Those are not perfect cost measures, but they are good enough to show that absolute reward is not the whole story.
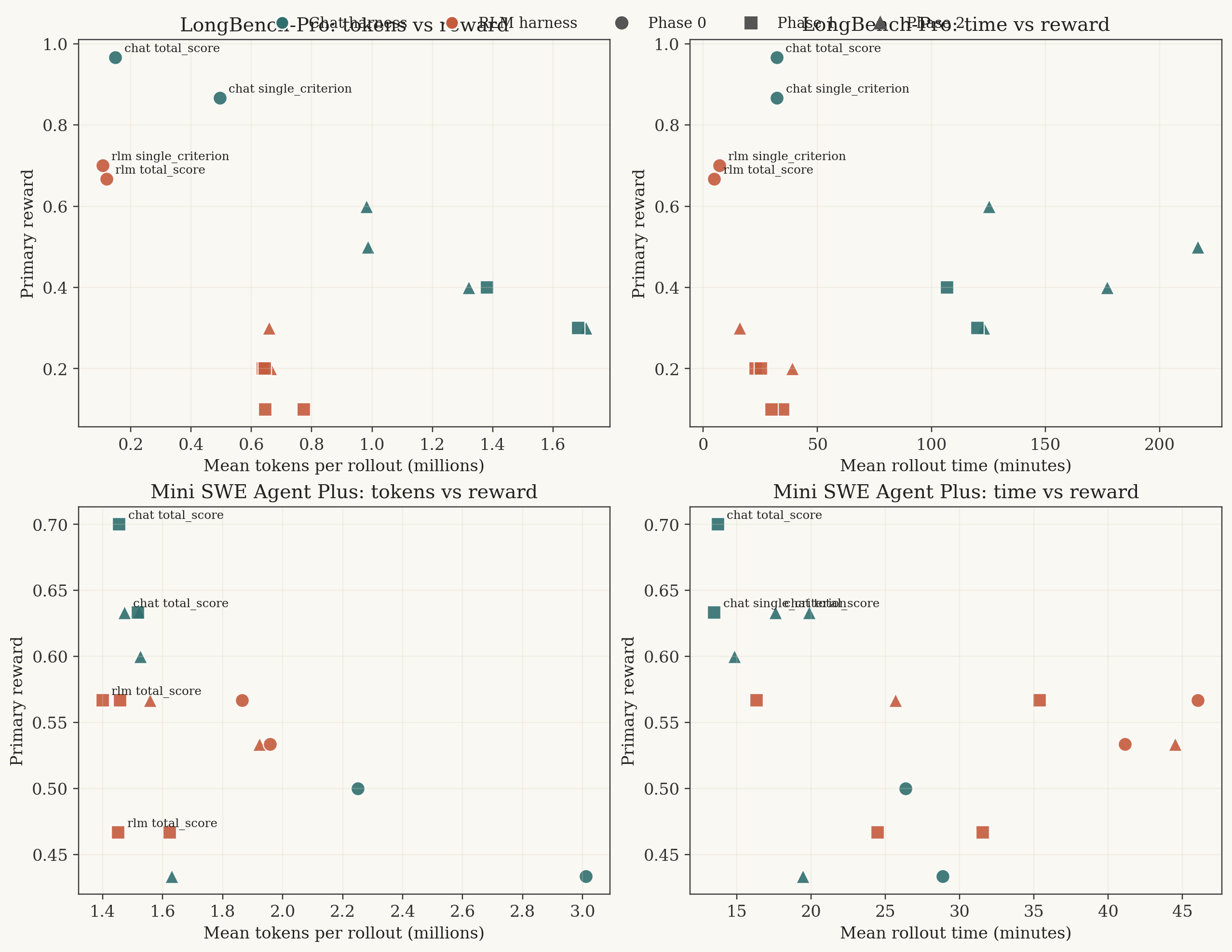
The tradeoff is benchmark-specific: on LongBench-Pro the RLM arms are often cheaper but worse; on Mini SWE the best chat arms usually dominate on quality and latency together.
LongBench-Pro efficiency
On the full Phase 0 LongBench-Pro run, chat won on absolute quality, but not on speed.
| Arm | Reward | Tokens / rollout | Mean rollout time (min) |
|---|---|---|---|
chat__total_score | 0.9667 | 149,192 | 32.2 |
rlm__single_criterion | 0.7000 | 106,936 | 7.0 |
rlm__total_score | 0.6667 | 119,868 | 4.8 |
So the absolute winner was dense chat, but the efficiency picture is mixed. Measured as reward per 100k tokens, rlm__single_criterion was actually a hair ahead of dense chat (0.6546 vs 0.6479). Measured as reward per rollout-hour, rlm__total_score was far ahead (8.28 versus 1.80), simply because the REPL loop terminated so much faster.
That is an important caveat to the plain "chat wins" reading. On LongBench-Pro, the RLM harness was often a cheap under-shooter, not an obviously wasteful one.
The same basic tension survives on the hard Phase 2 slice. The best chat arm, chat__single_criterion__chat_system_reinject, reached 0.6000 but needed about 980,901 tokens and 125.2 minutes per rollout. rlm__single_criterion__rlm_skill_file only reached 0.3000, but did so at 659,205 tokens and 16.0 minutes. So if the goal is best absolute answer, chat still wins. If the goal is getting a middling answer cheaply, the RLM harness is not dead at all.
Mini SWE efficiency
Mini SWE is much less kind to the RLM story.
In Phase 0, the tradeoff was still muddy rather than clean:
| Arm | Solved rate | Tokens / rollout | Mean rollout time (min) |
|---|---|---|---|
rlm__total_score | 0.5667 | 1,864,276 | 46.0 |
chat__single_criterion | 0.5000 | 2,250,750 | 26.4 |
Then Phase 1 happens, and the simple chat notebook arm becomes hard to ignore:
| Arm | Solved rate | Tokens / rollout | Mean rollout time (min) |
|---|---|---|---|
chat__total_score__mem_chat | 0.7000 | 1,455,311 | 13.7 |
rlm__total_score__mem_repl_files | 0.5667 | 1,399,685 | 16.3 |
rlm__total_score__mem_chat | 0.4667 | 1,451,797 | 24.5 |
That is the kind of result I trust more than any rhetoric. The winning chat arm is not only better in reward; it is also faster than every RLM arm and roughly comparable or better in token use. By Phase 2, the same broad pattern remains: the best Mini SWE chat cells dominate the quality/latency frontier, while the RLM skill-file cells often spend more time and still trail on actual solves.
So the short version is this:
- On LBP, absolute quality and efficiency pull in different directions.
- On Mini SWE, the best chat cells are usually just better overall.
So What does this lead to?
The most honest answer is: it learned that sparse signal is not a magic solvent, and that "more scaffold" is not the same thing as "better management."
I would compress the empirical takeaways like this.
- The central Phase 0 question did not resolve into a simple RLM win. On LongBench-Pro, chat plus dense feedback was best by a wide margin. On Mini SWE, chat liked sparse feedback while RLM liked dense feedback.
- Judge format and true task success can diverge in uncomfortable ways. On LongBench-Pro, judge success and task metrics were already not perfectly aligned; on Mini SWE, the judge could become wildly optimistic, especially for RLM skill-file arms.
- Working memory location mattered less than I expected. Moving notes from chat into files did not reliably help. In some places it did nothing. In some places it looked worse.
- Procedure persistence helped most when it stayed small and nearby. The best Phase 2 LongBench-Pro arm was system reinjection, not a persistent skill file. That is a point in favor of constrained carry-over over unconstrained diaries.
- Efficiency changes the interpretation. On LongBench-Pro, RLM often lost on absolute reward but remained competitive or better on reward-per-token and reward-per-time. On Mini SWE, by contrast, the best chat cells were usually better on all three axes.
- The outputs folder justifies its own messiness. The pilots were noisy, the serious rerun was cleaner, and the raw rows often told a more interesting story than the summary tables did.
- Structured state persistence RLMs may benefit from persistence, but only if the object being persisted is disciplined enough to be useful. The skill-file results suggest that the problem is not whether state survives between turns — it is whether the structure of that state constrains the model toward better next moves. A free-form diary accumulates just as readily as it clarifies. What Phase 2 hints at, without proving, is that a tighter schema might do more work than a richer one. The hypothesis is not "more memory good." It is "the right shape of memory, at the right moment, might change what the loop does next."
- Early failure Several RLM rollouts terminated earlier than their chat counterparts, and the first instinct is to read that as a loss. But there is a more interesting interpretation available. RLMs seem to front-load their exploration — probing the environment, testing tool boundaries, and discovering what the harness will and will not support — before committing to a refinement strategy. That means failures arrive sooner, which is not the same as failing more. A loop that surfaces a dead end in turn two is doing something structurally different from one that wanders into the same dead end at turn eight after burning tokens on confident-sounding intermediate steps. The RLM is not collapsing early. It is learning early. Whether the harness is well-designed enough to do anything useful with that signal is a separate question — and probably the more important one.
MGH, Continual Learning, And The Limits Of Notebook Optimism
I think these experiments fit surprisingly well between two broader ideas that have been circulating in this area, though not in the triumphant way one might first expect.
The mismanaged geniuses hypothesis argues that current models are underused because our scaffolds are clumsy. These runs support part of that claim. Small changes to management do matter. A different judge format can swing Phase 0 Mini SWE chat from 0.4333 to 0.5000. System reinjection can move Phase 2 LongBench-Pro from 0.3000 to 0.6000. The manager is not decorative.
But these runs also push against a lazy version of MGH, namely the version where every extra layer of scaffold is presumed to unlock more latent intelligence. That is not what happened here. Often the heavier harness did worse. Often the durable file did not help. Sometimes the simplest chat loop was both better and cheaper because it converged faster.
This is why the idea of the space of decompositions matters so much. The crucial question is not whether the model can store more notes. It is whether the harness induces the right decomposition of the problem. A bad notebook is still bad management.
A different but related point is that harness memory does not automatically scale into genuine continual learning. Retrieval can become the bottleneck; persistence can accumulate junk as easily as skill; external memory can plateau because the model underneath never changed.
Ilija Lichkovski opens a useful framing in a thread on defining continual learning for LLMs. In a reply there, @willccbb states the contrast more bluntly: with harness-based memory, growing a skill tree can show diminishing returns or even hurt performance, because the parametric model underneath is unchanged; parametric knowledge, by contrast, changes how much useful "intelligence" fits in a forward pass and is where compounding has more headroom—if you can solve continual learning in weights.
Phase 2 feels like a tiny, almost toy-sized version of that argument. A skill file does not automatically compound into better performance. If the feedback surface is misaligned, durable process memory can stabilize the wrong habits. In Mini SWE, the clearest example is the dense RLM skill-file arm: 29/30 judge acceptances, 17/30 real solves. That is not continual learning. That is durable overfitting to the wrong critic.
So I end up with a more skeptical version of the original optimism.
Yes, management matters.
No, persistence alone is not management.
And no, one should not confuse "the model learned a reusable procedure" with "the model got better at the task" unless the reward surface itself is trustworthy.
Caveats
There are several ways this experimental setup could mislead us if we read it too triumphantly.
First, this is still mostly a prompting study, not an RL study. The motivating question is about what refinement strategy an RLM develops. These runs tell us whether the scaffold changes behavior at inference time under fixed models. That is useful, but it is not yet evidence about learned decomposition.
Second, the comparisons are not perfectly apples-to-apples. On LongBench-Pro, the chat harness sees the whole context directly in the conversation, whereas the RLM harness has to work through a copied context.txt in the REPL. That means the RLM arm is not just "the same task with more tools"; it is also solving a slightly different interface problem.
Third, the later phases are on different slices. LongBench-Pro Phase 1 and Phase 2 are on a harder clustering slice at 32k context; Mini SWE Phase 1 and Phase 2 are narrowed to a single Django slice. This makes within-phase comparisons much cleaner than across-phase comparisons.
Fourth, the sample counts are not large enough to support chest-thumping. The serious LongBench-Pro Phase 1 and Phase 2 runs are only 10 rollouts per cell. That is enough to see directionality, not enough to declare subtle effects settled.
Fifth, the judge is a moving part in the experiment rather than an oracle above it. On Mini SWE especially, it can be wrong in the optimistic direction. That means some of the apparent "learning" in the loop may really be adaptation to judge taste.
Sixth, infrastructure noise is real. The Mini SWE sparse-reinject chat arm in Phase 2 had 8 sandbox startup failures. That does not invalidate the run, but it does mean not every low score is a pure behavioral fact about the model.
And finally, the skill-file intervention in Phase 2 is not really continual learning in the strong sense. It is durable external process memory within an episode family. Nothing is being internalized into weights, and nothing here proves cross-task accumulation of skill.
If I Wanted RLMs To Truly Shine
I do think this experimental setup is slightly harder on RLMs than the strongest possible RLM setting would be. Not unfairly hard, exactly. Just not optimized for the kinds of advantages RLMs are supposed to have.
If I wanted to build a better proving ground for them, I would change at least five things.
- Match the budget, not just the turn count. Fixed
max_turnsis not a fair compute budget across chat and REPL loops. I would compare under matched token budgets, matched wall-clock budgets, and matched dollar budgets. - Give RLM-native tasks more room to be RLM-native. LongBench-Pro is decomposable, but the current setup does not strongly encourage the chunking, batching, and reusable retrieval subroutines that make a recursive harness interesting.
- Reward the decomposition, not only the final answer. Especially for RLMs, intermediate evidence quality matters: did the model search the right chunks, keep the right notes, avoid repeated dead ends, or build a useful skill file? Right now those behaviors only matter indirectly through the final verdict.
- Train the harness rather than only prompt it. A lot of the current results feel like untrained scaffold sensitivity. That is valuable, but RLMs are really making a stronger claim: not just that they can externalize state, but that they can learn how to externalize and reuse it well.
- Use tasks with repeated structure and real horizon. RLMs should benefit most when there are many subproblems, when local failures can be logged and avoided, and when one good abstraction can pay off several times.
My suspicion is that a better RLM benchmark would look less like "chat, but with a REPL" and more like "a problem where decomposition itself is the scarce resource." Something like long-context retrieval with explicit chunk scheduling, or coding tasks with repeated diagnosis-and-repair motifs, or even multi-instance curricula where the same style of failure recurs often enough that a skill file can actually amortize.
In other words: if the goal is to let the RLM shine, the right question is not "how do we add more persistence?" It is "what environment makes good decomposition legible, learnable, and worth paying for?"
What I Would Try Next
The nice thing is that the current results already suggest the next experiments.
- Run the actual RL version of Phase 0. The real question is about what strategies an RLM develops. The current study mostly measures prompt-time scaffold sensitivity. That is useful, but it is still the prelude.
- Make judge disagreement a first-class metric on Mini SWE. Right now the big story is hidden unless you inspect the raw rollout logs. I would track judge-yes / test-no explicitly, per cell, and probably optimize against it.
- Use benchmark metrics more aggressively on LBP. The
[Answer] D/[Answer] Ccases are warning lights. If the judge and the task metric diverge, the report should treat that divergence as a result, not a footnote. - Constrain the persistent memory object harder. The skill file may simply be too unconstrained. I would try a tiny schema: maybe three fields only, something like
failure_pattern,next_check,don't_do_this_again. - Try cross-task carry-over, not just within-task persistence. Phase 2 is really episodic self-repair. The more interesting continual-learning question is whether procedure learned on one task helps on the next one without merely bloating the harness.
- Price the interventions properly. Some of the best-performing chat arms were also cheaper. On LBP Phase 0, dense chat did better and used far fewer mean tokens per rollout than sparse chat. That kind of Pareto win should become the baseline to beat.
Final Word
This line of experimentation isn't grandiose. It's quite simple. Change the signal. Change where the notes live. Change whether process can persist. Then inspect the logs closely enough that you cannot flatter yourself.
The answer, so far, is not that sparse feedback suddenly reveals the superiority of RLMs. It is not that a skill file quietly solves harness-level continual learning. It is not even that persistence is obviously good.
The answer is more awkward, and therefore more useful.
The signal matters. The language and structure of state persistence matters. But these things do not help monotonically, and they do not help equally across tasks. And sometimes, which is perhaps the healthiest outcome for a study like this, the experiment tells you that the story you wanted was a little too clean.
Credits
Grateful to @a1zhang and @willccbb for their insights and clear air for helping shape the direction of my inital exploration.
Appreciate @omouamoua and @rasdani_ for their thoughtful feedback, questions, and insights on directions to explore.
Also grateful to @kcoopm, @GottliebEli, and @samsja19 for helping debug and resolve hosted evals and run issues.
And of course, @vincentweisser, @johannes_hage, and the @PrimeIntellect team for the generous compute support, credits, and for hosted runs and evaluations.