Mixed Precision and ZeRO: Training Large Models Without Running Out of Memory
A note on mixed precision, high-precision parameter copies, and ZeRO.
TL;DR
Training large neural networks requires two conflicting desiderata: (1) the speed and memory economy of low-precision compute (FP16 / BF16), and (2) the numerical fidelity of high-precision updates (FP32). The inevitable compromise is to maintain both a high-precision FP32 canonical copy of parameters and a low-precision compute copy; gradients are produced in low precision, then cast to high precision for optimizer arithmetic. When scale forces duplication across devices, ZeRO (Zero Redundancy Optimizer) shards optimizer state, gradients, and — in its strongest form — parameters, trading communication for memory. Below you’ll find the math, the sequence of operations, memory accounting, communication primitives, and some engineering optimizations.
(Frameworks — for example PyTorch and DeepSpeed — implement these ideas in C++/CUDA with many optimizations; the theory here is what they implement under the hood.)
Flow (how to read this note)
- State the single physical law we are trying to perform.
- Spell out floating-point mechanics (precision, dynamic range) and why they force a compromise.
- Give the canonical mixed-precision protocol: FP32 canonical copy, FP16 compute copy, cast gradient, optimizer in FP32, refresh.
- Account for memory: naive per-device, then data-parallel replication and the urge to shard.
- Introduce ZeRO: sharding optimizer state (ZeRO-1), gradients (ZeRO-2), and parameters (ZeRO-3).
- Summarize communication primitives and costs (all-reduce, reduce-scatter, all-gather).
- Explain why high-precision copies are required (numerical stability, Adam example).
- Walk through a working ZeRO-1 protocol step by step.
- List engineering optimizations (bucketing, overlap, prefetch, grad scaling, offload).
- Give some practical recipes.
- Note common failure modes.
- Close with the ledger metaphor.
Prelude — the single physical law
There is only one true operation we are trying to perform:
where is the full parameter vector and is the update computed by your optimizer (for SGD ; for Adam it is a more elaborate function of past gradients). Computers approximate reals with floating point. That approximation imposes constraints that force the whole engineering stack you now know exists.
Floating-point mechanics
Floating point numbers are finite encodings of real numbers. IEEE-754 binary formats represent a number as:
where is the sign bit, the exponent field, the bias, and the significand bits. Two consequences matter for training:
- Precision (significand length). FP16 has 10 significand bits (≈3 decimal digits); BF16 preserves the wider exponent range of FP32 but with fewer significand bits; FP32 has 23 significand bits (≈7 decimal digits).
- Dynamic range (exponent). BF16 and FP32 share greater exponent range than FP16; overflow/underflow behavior depends on exponent fields.
Implication for updates. If and the update , FP16 may not represent when added to — the result rounds back to . Thus, performing repeated incremental updates in low precision leads to loss of meaningful progress.
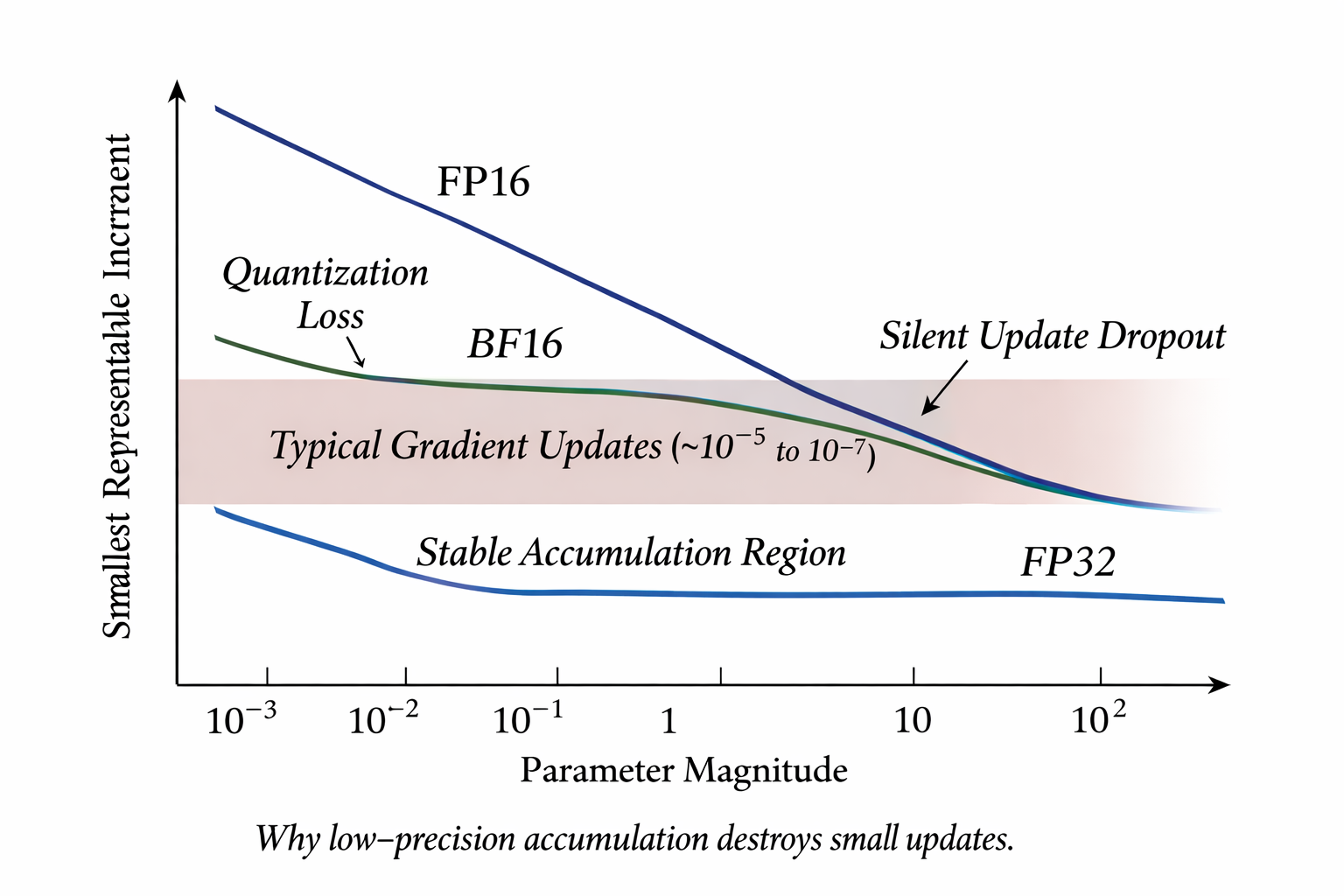
The canonical mixed-precision protocol (exact sequence)
From the physical constraints above, the robust protocol used in modern training is:
- Maintain a high-precision FP32 canonical parameter copy (FP32). This is the authoritative value.
- Maintain a low-precision compute copy (FP16 or BF16) used in forward/backward.
- During backward, compute low-precision gradients (initially FP16/BF16).
- Convert gradients to FP32: .
- Perform optimizer arithmetic in FP32 updating (and optimizer state like moments in FP32).
- Refresh compute copy: .
In symbolic form:
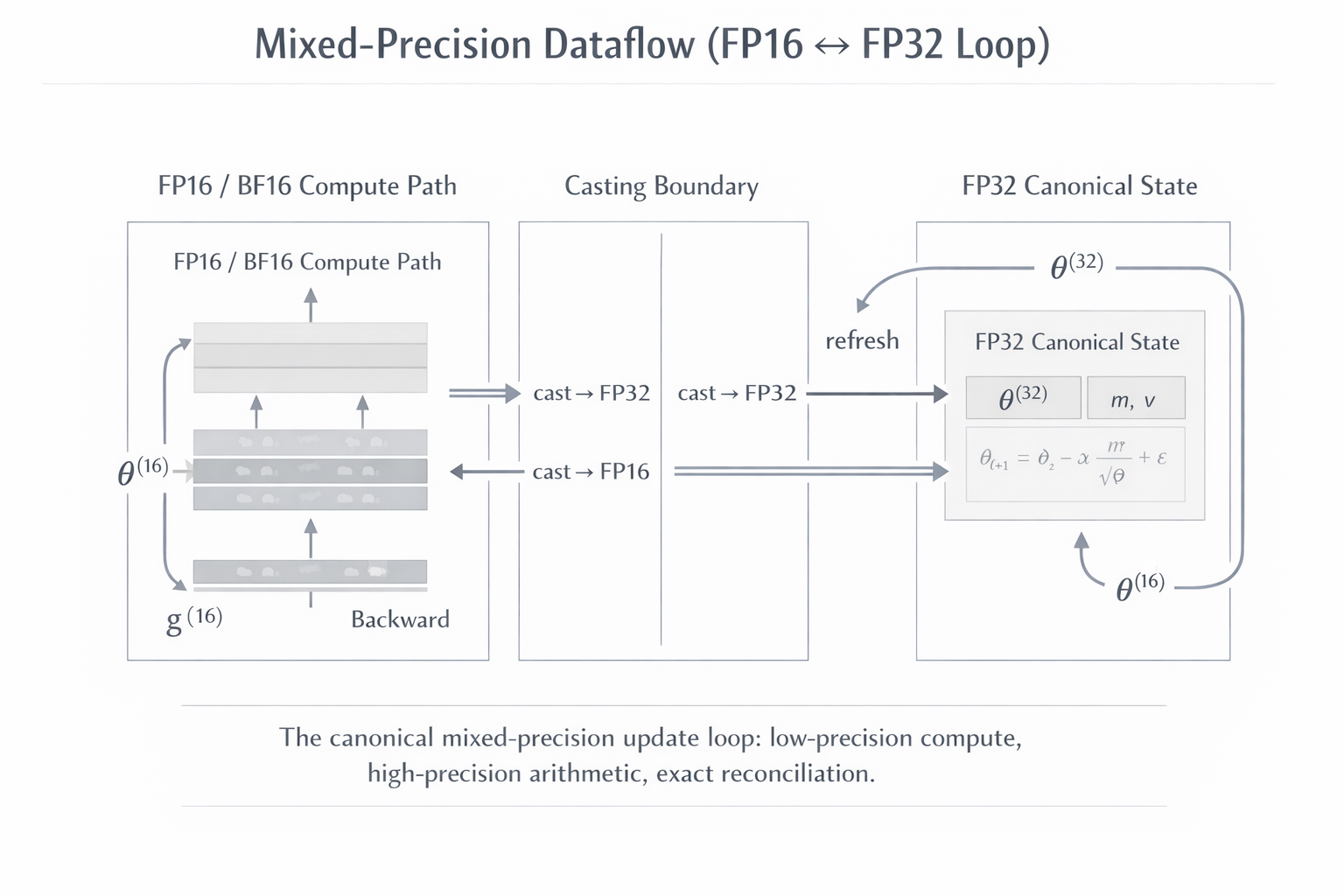
Why both copies? Because the optimizer math requires the dynamic range and precision of FP32 to preserve small incremental updates and accumulated moments; the compute path benefits from the throughput of low precision on modern tensor cores.
Memory accounting
Let denote the number of scalar parameters. Let element sizes be and bytes (2 and 4 bytes). Let denote the optimizer multiplier: the number of parameter-sized FP32 tensors the optimizer keeps (for Adam with FP32 canonical copy, : exp_avg, exp_avg_sq, FP32 canonical copy; retain symbolic for clarity).
Naive per-device memory (single replica, no sharding):
- FP16 parameters:
- FP32 canonical weights:
- Optimizer states:
- Gradients (peak): ≈ before casting, then (short lived)
So peak model-related memory (ignoring activations) is roughly:
Plugging , and yields a concrete feeling: per parameter ≈ bytes. For billion-parameter models this becomes terabytes.
Data-parallel replication. If you replicate the above across data-parallel devices, you multiply the model-related memory by . Thus the urgency to shard.
ZeRO
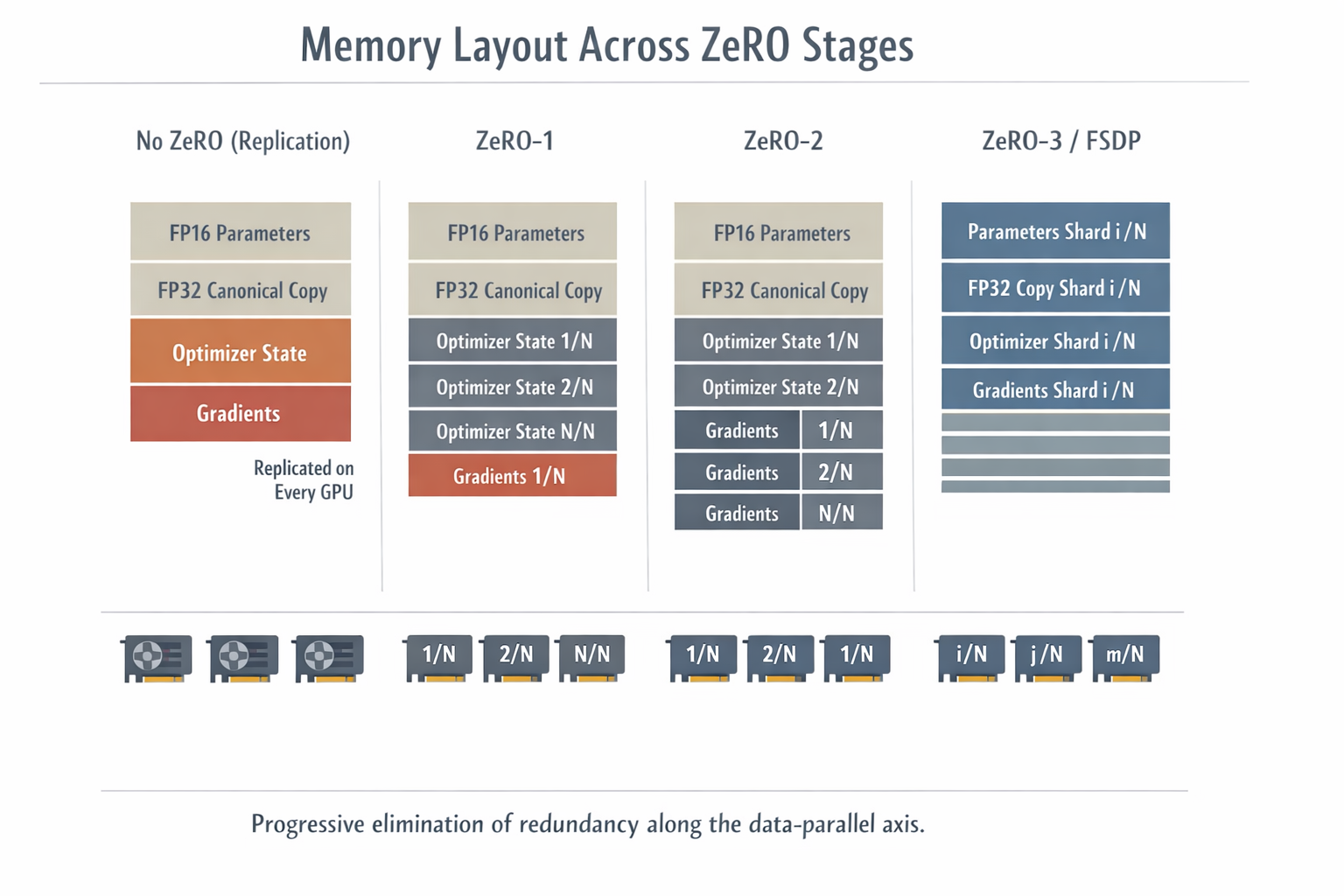
ZeRO shards along the data-parallel axis to remove redundancy. Let be DP degree.
Define three boolean indicators whether an object is sharded: for parameters, for gradients, for optimizer state. If an object is sharded, its contribution to per-rank memory divides by .
Per-rank model memory (excluding activations) is:
where encodes whether gradients are kept as FP16 then cast or kept in FP32 (use for FP32 grad accumulation). We can simplify for common cases.
ZeRO-1 (optimizer state sharded)
, , .
Per-rank memory:
Interpretation: parameters and gradients still replicated; only optimizer state is sharded.
ZeRO-2 (optimizer state + gradients sharded)
, , .
Per-rank memory:
Here gradient and optimizer state both scale down by .
ZeRO-3 (full sharding; parameters also sharded; a.k.a. FSDP)
, , .
Per-rank memory:
As grows, the model-related memory per rank can shrink arbitrarily (activations remain unsharded unless other techniques are applied).
Note about activations. Activation memory does not replicate across DP ranks — activations differ per micro-batch. Thus ZeRO cannot reduce activation memory; use activation checkpointing or sequence/batch strategies to reduce activation footprint.
Communication primitives and costs
Three collectives matter:
- All-reduce: every rank gets the fully reduced tensor. Cost roughly size network traffic (reduce + broadcast) in classical implementations; efficient implementations reduce constants.
- Reduce-scatter: performs reduction and scatters shards so each rank receives one shard of the reduced result. It is cheaper than all-reduce when you only need shards.
- All-gather: every rank sends its shard and every rank receives the full concatenation.
ZeRO replaces an all-reduce on gradients (vanilla DP) with a reduce-scatter + local update + all-gather on parameters (ZeRO-1/2), or with continuous layerwise all-gathers during forward/backward (ZeRO-3).
Communication complexity per step (measured in parameter-sized data transferred) — denote as the size:
- Vanilla DP: gradients all-reduce cost ≈ .
- ZeRO-1/2: reduce-scatter gradients cost ≈ (distributed), plus an all-gather of parameters cost ≈ ; total ≈ but the pattern and overlap differ and memory pressure is substantially reduced.
- ZeRO-3: parameters are all-gathered layerwise — roughly of communication tax if done naively, but overlap/prefetching and grouping reduce wall-time overhead.
Latency vs bandwidth trade. Many small collectives incur latency; bulked transfers favor bandwidth. Engineering thus buckets parameters to balance per-call latency and per-byte throughput.
Precise numerical stability mechanics: why high-precision copies are required
Consider one scalar parameter and an update . In floating point:
- FP16 spacing near 1.0 is — updates of vanish.
- FP32 spacing near 1.0 is — updates of are preserved.
Thus to preserve the iterative accumulation of small updates, optimizer accumulation (moment estimates, bias corrections) must be maintained in FP32. Storing only FP16 copies will catastrophically quantize the update loop.
Adam example (exact): Adam update for parameter at step :
Each of , , , benefits from FP32 precision to avoid bias amplification and catastrophic cancellation; casting them to FP16 would destroy the algorithm’s internal fidelity.
A Working Protocol for ZeRO-1
Below is the precise step performed on each DP rank for ZeRO-1: optimizer-state sharding while parameters remain replicated in FP16.
-
Keep (full, local) and , , (sharded FP32 canonical pieces).
-
For a minibatch:
- forward using .
- backward producing local .
- flatten and pad to common size; compute reduce-scatter → receive gradient shard .
- cast and divide by if gradients are averaged.
- update local optimizer state and using Adam formulas above.
- cast local updated to FP16 → .
- all-gather → reconstruct full on each rank for next forward.
- zero gradients / manage buffers.
This sequence preserves mathematically identical parameter updates to the naive single-device FP32 update, up to floating point rounding differences introduced by different reduction order — which are typically negligible if using stable reduction algorithms.
Engineering optimizations
Some engineering levers that matter:
- Bucketed communications. Aggregate small tensors into buckets sized to saturate NIC bandwidth to amortize latency.
- Non-blocking collectives + overlap. Launch reduce-scatter as soon as a bucket’s gradients are ready (backward hooks). Launch parameter all-gathers as soon as a shard’s update is ready (optimizer step) and overlap with remaining optimizer computation.
- Prefetching in ZeRO-3/FSDP. While computing layer 's forward, prefetch (all-gather) parameters for layer .
- Meta device construction. Build architecture shapes on device=meta to avoid materializing full parameter tensors before sharding (saves memory on initialization).
- Grad scaling (AMP). Multiply loss by a scale to avoid FP16 overflow; unscale gradients before optimizer step and detect inf/nan to adjust .
- Offload. When device RAM is insufficient, offload rarely used optimizer state shards to CPU or NVMe with asynchronous I/O, overlapping transfers with compute.
- Checkpoint sharding. Save sharded state dicts; avoid gathering full parameter sets to a single node for checkpoint writes.
Practical recipes
A production checklist, from smallest to largest scale:
- Use AMP (autocast + GradScaler). Prefer BF16 on hardware that supports it if you can eliminate GradScaler safely.
- Use FSDP / ZeRO (library implementation) rather than writing manual sharding. Let the runtime handle hooks and bucketization.
- Combine ZeRO-2 / ZeRO-3 with activation checkpointing and gradient accumulation when activations are the bottleneck.
- Use per-layer prefetching and sensible FSDP unit sizes (don’t shard at too fine granularity).
- Profile: measure collective sizes, time spent waiting on NCCL, and memory peaks; tune bucket sizes and prefetch windows.
- Ensure deterministic reduction order only if you need bitwise reproducibility; otherwise prefer throughput-optimized reductions.
Common failure modes
- Loss explosion / NaNs. Often caused by overflow in FP16 matmuls. Grad scaling prevents this: multiply loss by , compute gradients, then divide by before updating.
- Stalled training (no progress). Often caused by updates being lost to quantization if you tried to update exclusively in FP16. The theory above shows why a high-precision FP32 canonical copy is required.
- Excessive communication overhead. Happens when bucket sizes are too small: latency dominates. The communication model above explains why aggregating transfers increases effective bandwidth.
- Activation OOM even with ZeRO-3. ZeRO reduces model-related memory, not activations; employ checkpointing and accumulation to reduce activation peaks.
Closing remark
- FP32 canonical copy = the ledger in the bank. It is the canonical truth, carefully recorded.
- FP16 compute copy = the working checkbook. You do the arithmetic quickly here and then reconcile with the ledger.
- ZeRO sharding = splitting the ledger’s pages across vaults. Each vault keeps its pages and returns photocopies when needed.